Fuente
https://www.toptal.com/algorithms/algoritmos-gen%C3%A9ticos-b%C3%BAsqueda-y-optimizaci%C3%B3n-por-selecci%C3%B3n-natural/es
https://www.toptal.com/algorithms/algoritmos-gen%C3%A9ticos-b%C3%BAsqueda-y-optimizaci%C3%B3n-por-selecci%C3%B3n-natural/es
En los últimos años, ha habido un alboroto en relación con la Inteligencia Artificial (IA). Las grandes compañías como Google, Apple y Microsoft trabajan activamente en este tema. De hecho, la IA es solo paraguas que cubre muchas metas, acercamientos, herramientas y aplicaciones. Los Algoritmos Genéticos (AG) son solo una de las herramientas inteligentes que buscan a través de muchas soluciones posibles.
El AG es una búsqueda meta-heurística al igual que una técnica de optimización basada en principios presentes en la evolución natural. Pertenece a una clase más larga de algoritmos evolutivas.
El AG mantiene una población de cromosomas—un set de soluciones posibles para el problema. La idea es que la “evolución” encuentre una solución óptima para el problema después de un número de generaciones sucesivas—similar a una selección natural.
El AG imita tres procesos evolutivos: selección, entrecruzamiento cromosómico y mutación.
Tal como la selección natural, el concepto central de la selección AG es la adaptación. Los cromosomas que se adaptan mejor tienen una mayor oportunidad de sobrevivir. La adaptación es una función que mide la calidad de la solución representada por el cromosoma. En esencia, cada cromosoma dentro de la población representa los parámetros de entrada, como el volumen y precio de cambio, cada cromosoma, lógicamente, consistirá de dos elementos. Como los elementos están codificados dentro del cromosoma es otro tema.
Durante la selección, los cromosomas forman parejas de padres para la reproducción. Cada niño toma características de sus padres. Básicamente, el niño representa una recombinación de características de sus padres: Algunas de las características son tomadas de un padre y otras del otro padre. Adicionalmente a la recombinación, algunas de las características pueden mutar.
Ya que los cromosomas más adecuados producen más niños, cada generación subsecuente será más adecuada. En algún punto, una generación contendrá un cromosoma que representará una solución lo suficientemente buena para nuestro problema.
El AG es poderoso y ampliamente aplicable a problemas complejos. Hay una clase extensa de problemas de optimización que son un tanto difícil de resolver usando técnicas convencionales de optimización. Los algoritmos genéticos son algoritmos eficientes que poseen soluciones aproximadamente óptimas. Las ya bien conocidas aplicaciones incluyen programación, transporte, planificación de ruta, tecnologías de grupo, diseño de plano, entrenamiento de red neural y muchos otros.
Poniendo las Cosas en Práctica
El ejemplo que veremos puede ser considerado el “Hello World” de AG. Este ejemplo fue presentado inicialmente por J. Freeman en Simulating Neural Networks with Mathematica. Yo lo tomé de Genetic Algorithms and Engineering Design por Mitsuo Gen y Runwei Cheng.
El problema simulador del mundo intenta evolucionar una expresión con un algoritmo genético. Inicialmente, el algoritmo debe “adivinar” la frase “ser o no ser” de listas de letras generadas al azar.
“Ya que hay 26 letras posibles para cada una de las 13 locaciones [excluyendo espacios en blanco] en la lista, la posibilidad de que obtengamos la frase correcta puramente al azar es (1/26)^13=4.03038×10-19, lo cual es aproximadamente dos chances en un [trillón]” (Gen & Chong, 1997).
Vamos a definir el problema un poco más aquí al hacer la solución aún más difícil. Asumamos que no estamos limitados a la lengua inglesa, o una frase específica. Podemos terminar lidiando con cualquier alfabeto, o hasta cualquier set de símbolos. No tenemos conocimiento de la lengua. Ni siquiera sabemos si hay algún idioma.
Digamos que nuestro oponente pensó en una frase arbitraria, incluyendo espacios en blanco. Sabemos el largo de la frase y la cantidad de símbolos en el alfabeto. Ese es el único conocimiento que tenemos. Después de cada suposición, nuestro oponente nos dice cuántas letras se encuentran en su lugar.
Cada cromosoma es una secuencia de índices de los símbolos en el alfabeto. Si hablamos del alfabeto inglés, entonces ‘a’ será representada por 0, ‘b’ por 1, ‘c’ por 2, y así sucesivamente. Entonces, por ejemplo, la palabra “ser” será representada como
[4, 1].
Vamos a demostrar todos los pasos a través de trozos de código Java, pero el conocimiento en Java no es un requerimiento para entender cada paso.
El Centro del Algoritmo Genético
Podemos empezar con la implementación general del algoritmo genético:
public void find() {
// Initialization
List<T> population = Stream.generate(supplier)
.limit(populationSize)
.collect(toList());
// Iteration
while (!termination.test(population)) {
// Selection
population = selection(population);
// Crossover
crossover(population);
// Mutation
mutation(population);
}
}
Este es un set de pasos simples que todo AG debería tener. En el paso inicial, generamos una población inicial de frases. El tamaño de la población está determinada por
populationSize. Y como se genera esta frase depende de la implementación del supplier.
Dentro del paso de iteración, evolucionamos la población hasta que se dan las condiciones de término, dentro de la prueba de nudo
while. Las condiciones de término pueden incluir el número de generaciones y la pareja perfecta de una de las frases en la población. El termination encapsula una implementación exacta.
Dentro de cada iteración, hacemos los típicos pasos de AG:
- Lleva a cabo una selección sobre la población en adecuación de cromosomas.
- Produce una nueva “generación” vía la operación de entrecruzamiento.
- Lleva a cabo una recombinación de algunas letras en algunas frases.
El centro del algoritmo es muy simple y de dominio agnóstico. Sería el mismo para todo los problemas. Lo que debes ajustar es la implementación de operadores genéticos. Luego, miraremos más de cerca a cada uno de los ya mencionados operadores AG.
Selección
Como ya sabemos, la selección es un proceso hecho para encontrar sucesores para los cromosomas actuales—los cromosomas que sean más adecuados para nuestro problema. Durante la selección, necesitamos asegurar que los cromosomas con mejor adecuación tienen más chance de sobrevivir.
private List<T> selection(List<T> population) {
final double[] fitnesses = population.stream()
.mapToDouble(fitness)
.toArray();
final double totalFitness = DoubleStream.of(fitnesses).sum();
double sum = 0;
final double[] probabilities = new double[fitnesses.length];
for (int i = 0; i < fitnesses.length; i++) {
sum += fitnesses[i] / totalFitness;
probabilities[i] = sum;
}
probabilities[probabilities.length - 1] = 1;
return range(0, probabilities.length).mapToObj(i -> {
int index = binarySearch(probabilities, random());
if (index < 0) {
index = -(index + 1);
}
return population.get(index);
}).collect(toList());
}
La idea de esta implementación es la siguiente: La población es representada como rasgos consecuentes en el eje numérico. La población completa está entre 0 y 1.
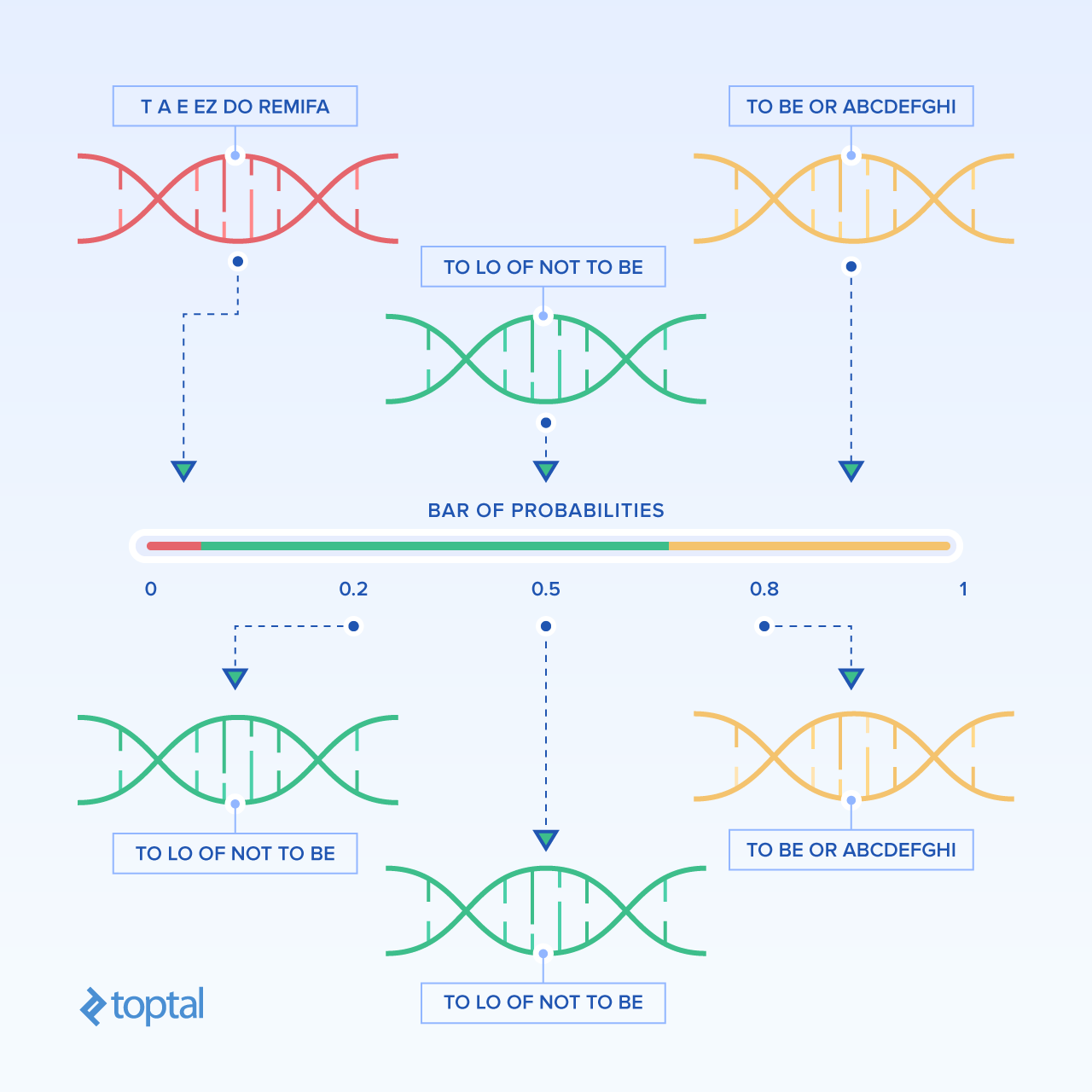
El trozo de la serie que toma un cromosoma es proporcional a su adecuación. Esto da como resultado un cromosoma mucho más adecuado el cual toma un trozo más grande. Luego escogemos un número al azar entre 0 y 1 y encontramos una serie que incluye este número. Obviamente, las series más grandes tienen mejor oportunidad de ser seleccionados, por ende, los cromosomas más adecuados tienen mejor oportunidad de sobrevivir..
Ya que no conocemos detalles sobre la función de la adecuación, necesitamos normalizar los valores de adecuación. La función de adecuación es representada por
fitness, la cual convierte a un cromosoma en un doble arbitrario que representa la adecuación del cromosoma.
En el código, encontramos una tarifa de adecuación para todos los cromosomas en la población y también encontramos la adecuación total. Dentro del nudo
for, ejecutamos una suma acumulativa sobre probabilidades disminuidas por adecuación total. Matemáticamente, esto debería resultar en la variable final teniendo un valor de 1. Debido a la imprecisión del punto flotante, no podemos garantizar eso, así que lo ajustamos a 1 para estar seguros.
Finalmente, por una cantidad de tiempo igual al número de cromosomas entrantes, generamos un número al azar, encontramos una serie que incluya el número y luego seleccionamos el cromosoma correspondiente. Como debes haber notado, el mismo cromosoma puede ser seleccionado muchas veces.
Entrecruzamiento
Ahora necesitamos que los cromosomas se “reproduzcan.”
private void crossover(List<T> population) {
final int[] indexes = range(0, population.size())
.filter(i-> random() < crossoverProbability)
.toArray();
for (int i = 0; i < indexes.length / 2; i++) {
shuffle(Arrays.asList(indexes));
final int index1 = indexes[2 * i];
final int index2 = indexes[2 * i + 1];
final T value1 = population.get(index1);
final T value2 = population.get(index2);
population.set(index1, crossover.apply(value1, value2));
population.set(index2, crossover.apply(value2, value1));
}
}
Con la probabilidad predefinida como
crossoverProbability, seleccionamos padres para la reproducción. Los padres que sean seleccionados son mezclados, permitiendo así que se de cualquier combinación. Tomamos parejas de padres y aplicamos el operador crossover. Aplicamos el operador dos veces para cada pareja porque necesitamos mantener el mismo tamaño de la población. Los niños reemplazan a los padres en la población.Mutación
Finalmente, llevamos a cabo la recombinación de las características.
private void mutation(List<T> population) {
for (int i = 0; i < population.size(); i++) {
if (random() < mutationProbability) {
population.set(i, mutation.apply(population.get(i)));
}
}
}
Con la probabilidad
mutationProbability predefinida, llevamos a cabo la “mutación” en los cromosomas. La mutación como tal es definida como mutation.Configuración de Algoritmo de Problema-Específico
Ahora echemos un vistazo a qué tipo de parámetros de problema específico necesitamos proveer para nuestra implementación genérica.
private BiFunction<T, T, T> crossover;
private double crossoverProbability;
private ToDoubleFunction<T> fitness;
private Function<T, T> mutation;
private double mutationProbability;
private int populationSize = 100;
private Supplier<T> supplier;
private Predicate<Collection<T>> termination;
Los parámetros, respectivamente, son: 1. Operador de entrecruzamiento 2. Probabilidad de entrecruzamiento 3. Función de adecuación 4. Operador de mutación 5. Probabilidad de mutación 6. Tamaño de la población 7. Proveedor de cromosomas para la población inicial 8. Función de término
Aquí está la configuración de nuestro problema:
new GeneticAlgorithm<char[]>()
.setCrossover(this::crossover)
.setCrossoverProbability(0.25)
.setFitness(this::fitness)
.setMutation(this::mutation)
.setMutationProbability(0.05)
.setPopulationSize(100)
.setSupplier(() -> supplier(expected.length))
.setTermination(this::termination)
.find()






























No hay comentarios:
Publicar un comentario